|
|
Korenine / Origin / Herkunft |
|


| © korenine.si | Podpora |
|
||||||||||||||
| Origin | Conference | News | Proceedings | About us | Links | Donations |
|
|
|
LINGUISTIC COMPUTATIONAL ANALYSIS TO MEASURE THE DISTANCES BETWEEN ANCIENT VENETIC, LATIN, AND SLOVENIAN LANGUAGES
M. Silvestri1, Giancarlo Tomezzoli2 1 Via Faliero 16, I-37138 Verona , Italy 2 Zeppelinstrasse 43, D-81669 Munich, Germany
Abstract In this paper we analyse the linguistic distances between the ancient Venetic, Latin, and Slovenian languages. The first step of the work consisted of the construction of three electronic language corpuses: - The Venetic Language Database (VLD), comprising all the Venetic inscriptions in the works of Pellegrini&Prosdocimi, Marinetti, and other Internet sources; - The Latin Language Database (LLD), comprising works of the Latin writers: Plautus, Cato, Terence, Cicero, Caesar, Vergil, Propertius, active in the period 300 – 0 BC, a period in which the Latin and the Venetic languages were spoken practically independently; - The Slovenian Language Database (SLD), comprising the texts of the most ancient Slovenian manuscripts: the Brižinski spomeniki (Freisinger Denkmäler I-III), the Rateški rokopis (Ratetischer Handschrift), the Stiški rokopis (Sitticher Handschrift), the Starogorski rokopis (Handschrift von Castelmonte). Mainly because the subdivision in words, the pronunciation, the linguistic evolution, the exact meaning of the punctuation rules of the Venetic are unknown, the techniques for calculating the linguistic distances used in recent publications by Nerbonne, Kessler, Heeringa, Kruskal, and Vieregge are not applicable. Therefore, we developed a simple and direct method for evaluating said linguistic distances. Using the Euclidean distance algorithm, within the limit of the corpuses considered, we were able to calculate the linguistic distances between the ancient Venetic, Latin, and Slovenian. Our calculations indicate that Venetic has a Euclidean distance closer to the Slovenian (1.809) than to the Latin (5.295). This appears to disprove the Lejeune’s statement that “This language (the Venetic) is “Italic” and … closer to the Latin than any other language”, and appears to confirm that Bor was right in setting forth that similarities between Venetic and modern Slovenian, its surviving dialects and all Slovenian archaisms, can be used for interpreting the Venetic inscriptions. This would confirm the hypothesis set out by Šavli, Bor and Tomažič, that the Venetic in Veneto province, Italy, rapidly disappeared due to romanization, while Slovenian preserved part of the Venetic.
Introduction The origin of the Venetic language has been debated for a relatively long time by many authors such as Pellegrini and Prosdocimi [1], Marinetti [2], Lejeune [3], Šavli, Bor and Tomažič [4]. All these authors agreed that the Venetic language is an Indo-European (IE) language, but they disagree about the fundamental question of the linguistic distance of the Venetic with respect to the Latin and the Slovenian languages. On one side, Lejeune [3] affirmed that: “This language (the Venetic) is “italic” and, …, closer to the Latin than any other language”. On the other side, Bor [4] affirmed that. “I was unable to find a single (Venetic) inscription that could not be deciphered on the basis of the Slavic languages and the surviving Slovenian dialects, above all the Slovenian archaisms” and Šavli and Tomažič [4] agreed that the Venetic is closer to the Slovenian. The problems in interpreting the Venetic consists in the relatively small number of inscriptions (about 400) which are in most of the cases short, broken or incomplete, making the composition of an extended and comprehensive linguistic Corpus difficult or impossible. In addition, the majority of the Venetic inscriptions are written in continuous graphics (“continuum”), i.e. without separation in words, and are mainly of funerary or votive content, so that they do not give us any clue about Venetic toponyms, verbs, and frequently used words that could be used for computational comparisons between the Venetic and other languages. The punctuation rules, probably linked to a possible syllabic structure of the Venetic, provided by Lejeune [3] and Vetter [5] are far from indicating clear word separations. Moreover, a further problem facing the use of computational techniques for comparing the Venetic with other languages is its still unknown possible pronunciation rules. Therefore, any attempt of classifying the Venetic by using phonetic symbolic techniques would be practically worthless. On one side, using the Lejeune [3] and Vetter [5] punctuation rules and possible similarities between Venetic and Latin, Pellegrini, Prosdocimi [1] and Marinetti [2] provided translations of a great number of the Venetic inscriptions. However, as clearly visible in their works, the translation in the majority of the cases is more an extrapolation of the possible meaning of the inscriptions than a clear translation. On the other side, Vodopivec [6] made a remarkable comparison between Venetic, Latin and Slovenian, as well as other languages: Kroatian, English, German, French, Italian, Greek. By considering different Venetic roots: vrv, trt, krk, …, grg; prap, …, prup, derived from the Venetic alphabetic tablets Es23 – Es26, he found that such roots exist mainly in the Slovenian and in the Kroatian languages. In addition, by using possible similarities between Venetic and Slovenian, Ambrozic and Tomezzoli [7] provided a complete translation of the long Venetic inscription on the “Tavola da Este”.
Materials and Methods
Latin, Slovenian, and Venetic Corpuses As the first step of our attempt to measure the linguistic distances between the ancient Venetic, Latin and Slovenian, we developed the following three electronic databases. - The Latin Language Database (LLD), which comprises the works of the following Latin authors: Plautus (250 – 184 BC) - Stichus, Cato (234 – 149 BC) - De Agri Cultura, Terence (195/185 – 159 BC - Hecyra, Cicero (106 – 43 BC) – Catilinariae I - IV, Caesar (100 – 44 BC) - De Bello Gallico I - VIII, Vergil (70 – 19 BC) - Aeneids I - XII, Propertius (50 – 16 BC) - Elegiae I - IV. All these Latin authors were active in the period 300 ~ 0 BC, a period in which the Latin and the Venetic languages were spoken almost independently. The texts of said authors were acquired from the Internet site: www.thelatinlibrary.com and stored in a first Word (.doc) file together with their relevant explanations and notes. - The Slovenian Language Database (SLD), which comprises the texts of the most ancient available Slovenian manuscripts: the Brižinski Spomeniki or Freisinger Denkmäler I-III (972 – 1093 AD), the Rateški Rokopis or Ratetischer Handschrift (1362 – 1390 A.D), the Stiški Rokopis or Sitticher Handschrift (1428 – 1440 AD), the Starogorski Rokopis or Handschrift von Castelmonte (1450 – 1520 A.D). Although far from the period in which the Venetic was currently spoken, these manuscripts represent, at the moment, the most ancient written sources of the Slovenian to be considered for linguistic comparisons. No written text has been found in Slovenian or Slovenian dialects earlier than these texts. The texts of the manuscripts were acquired from the Internet sites: http://www.kortlandt.nl/editions/freis.html , http://kodeks.uni-bamberg.de/AltSloven/Quellen/ASL.Ratetsch.htm , http://kodeks.uni-bamberg.de/AltSloven/Quellen/ASL.Sittich.htm http://kodeks.uni-bamberg.de/AltSloven/Quellen/ASL.Castelmonte.htm and stored in a second Word (.doc) file together with their relevant explanation and notes. - The Venetic Language Database (VLD), which comprises all the Venetic inscriptions in the works of Pellegrini, Prosdocimi [1] and Marinetti [2]. The texts of the inscriptions were manually stored in a third Word (.doc) file with explanations and notes, strictly respecting the conventions used by the authors.
The LLD is the most complete Corpus (1 018 924 characters), it contains texts of various subjects: poetical, agricultural, historical, epical, etc., but it is influenced by the linguistic evolution of the Latin in said period 300 ~ 0 BC. The SLD (10 982 characters) contains religious texts influenced by the linguistic evolution of the Slovenian over the period of about 400 years. The inscriptions in the VLD (9 655 characters) are influenced, in addition to the effects mentioned above, also by the following effects: - local alphabetic particularities (Este, Padua alphabets); - linguistic and alphabetic modifications of the Venetic in the of about period 500 ~ 0 BC; - the romanization in the last period of the Venetic independence.
Language Distance – Discussion Many computational techniques were used in the past for calculating the linguistic distances between languages, dialects or variants in same or different family languages. Nerbonne [8, 9, 10], Kessler [11], Heeringa [12] were successful in measuring Dutch and Irish dialects distances, in which the phonetics and the meaning of the words were known. The Levenshtein distance technique presented by Kruskal [13] and used by many other authors is also extremely reliable in the calculation of the phonetic distance when applied to Corpuses of well-known words having well known phonetics and grammar rules. By opposite, the problems of the Venetic, as discussed above, is that a large Corpus of words cannot be accessed, the exact meaning of the punctuation rules is unknown, the precise grammar rules are practically unknown, the subdivision in words is unknown and the exact pronunciation and linguistic evolution of the Venetic are still largely unknown. Thus, it is not possible to use the usual techniques: the Levenshtein distance, the frequency of phonetic features, the frequency per word, the Manhattan distance or hybrid techniques used by Vieregge et al. [14], for evaluating the linguistic distances between the ancient Latin, Slovenian and Venetic. For these reasons, we developed a much more simple and direct method for evaluation of said linguistic distances.
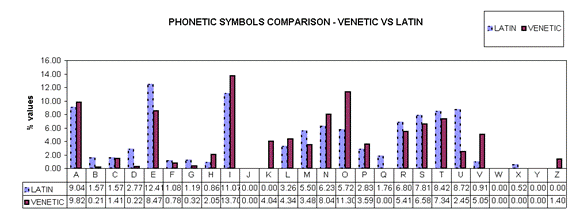
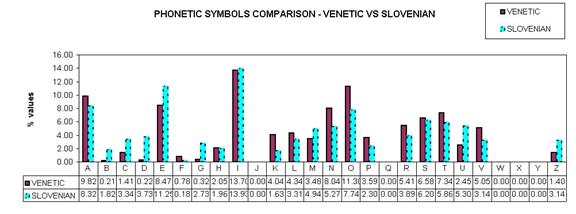
Data Aggregation As the second step, the texts of the original Word files of the LLD, SLD and VLD have been stored in three other Word (.doc) files in which explanations and notes were eliminated. As the third step, by applying the option Search + Count of the word processor Ultraedit to these last three Word (.doc) files, each vocalic alphabetic symbol, i.e.: A, E, …, in the texts of the LLD, SLD and VLD has been counted. The vocalic alphabetic symbol values found for each of the LLD, SLD, VLD have been put in an Excel file. Accordingly, by applying the option Search + Count of said word processor to said three last Word (.doc) files, each consonantic alphabetic symbol, i.e.: B, C, …, in the texts of the LLD, SLD and VLD has been counted. The consonantic alphabetic symbol values found for each of the LLD, SLD and VLD have been put in the same Excel file. As the fourth step, observing that several alphabetic symbols have the same sound and for permitting, as long as possible, a one-to-one correspondence between the alphabetic symbols in the different languages, the alphabetic symbols have been aggregated according to the following rules. For the Latin: - the AE has been aggregated with E; - the PH has been aggregated with F; - the J and Y have been aggregated with I. Overall the aggregation process does not change dramatically the scenario since these first symbols have a low presence in the value context. The aggregated alphabetic symbols values for the Latin have been put in a first dedicated column in said Excel file. For the Slovenian: - the W has been aggregated with U; - Y and J values have been aggregated with I. The aggregated alphabetic symbols values for the Slovenian have been put in a second dedicated column in said Excel file. For the Venetic: - VH has been aggregated with F (see Pellegrini, Prosdocimi [1]); - D, G , Z and P have been not aggregated because of their debated meaning and possible pronunciation in Venetic. However, since they all represent a very small number from a contextual perspective their eventual debated relationship with other symbols will be practically not perceptible once the values are computationally analyzed. The aggregated alphabetic symbols for the Venetic have been put in a third dedicated column in said Excel file. As the fifth step, the aggregated alphabetic symbols values for LLD, SLD, VLD in said Excel file have been normalized, and, by using the Excel graphical tools, have been represented in Figures 1, 2.
Figure 1. Aggregated alphabetic symbolic values for the LLD and VLD.
Figure 2. Aggregated alphabetic symbolic values for the VLD and SLD.
At the first glance, from Figures 1 and 2 it appears that, in the region of the alphabetic symbols I – V, the Slovenian fits a bit better the alphabetic symbols of the Venetic than the Latin.
Linguistic Distance – Application As the sixth step, by using alphabetic symbols from said last dedicated columns in said Excel file, the average alphabetic coordinates for the Venetic, Slovenian, Latin have been calculated according to the following algorithms, assuming the Latin as reference.
For the Venetic: 1) Xven = ? abs(Iven – Ilat) / Nvow 2) Yven = ? abs(Bven – Blat) / Ncons
For the Slovenian: 3) Xslo = ? abs(Islo – Ilat) / Nvow 4) Yslo = ? abs(Bslo – Blat) / Ncons
For the Latin, assumed as reference: 5) Xlat = ? abs(Ilat – Ilat) / Nvow = 0.0 6) Ylat = ? abs(Blat – Blat) / Ncons = 0.0.
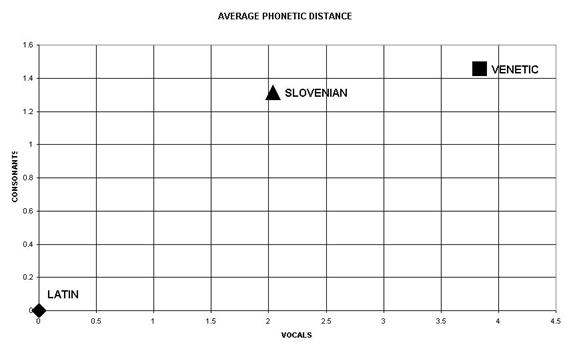
In these algorithms, I: means any vocalic symbol (A, E, I, O, U), B: means any consonantic symbol (B, C, etc.), subscript: ven means Venetic, subscript: slo means Slovenian, subscript: lat means Latin, Nvow: means the number (5) of different vowels taken into account, Ncons: means the number (19) of different consonants taken into account. The resulting average alphabetic coordinates are: Xven = 3.840, Yven = 1.455, Xslo = 2.036, Yslo = 1.314. The points (Xven,Yven), (Xslo,Yslo), (Xlat,Ylat) are represented in Figure 3.
Figure 3. The Average Phonetic Distance between Venetic , Slovenian , and Latin.
As the seventh step, the Pythagorean Linguistic Distances between Venetic and Latin, Slovenian and Latin, Venetic and Slovenian have been calculated by using the following algorithms: 7) Dpven/lat = [(Xven – Xlat)2 + (Yven – Ylat)2]1/2 8) Dpslo/lat = [(Xslo – Xlat)2 + (Yslo – Ylat)2]1/2 9) Dpven/slo = [(Xven – Xslo)2 + (Yven – Yslo)2]1/2 and represented in Table 1:
Table 1. Pythagorean Linguistic Distance between Latin, Slovenian, and Venetic languages. Lat. Ven. Slo. Lat. 0.0 5.295 3.350
Ven. 5.295 0.0 1.809
Slo. 3.350 1.809 0.0
It has to be observed that our Pythagorean Distance algorithm directly measures the linguistic distances between the three languages considered, but, apparently, it cannot measure other linguistic characteristics or factors normally used in linguistics to classify or compare different languages.
Results Figure 3 and Table 1 indicate that Slovenian, in the limits of the Corpuses considered, is closer to the Latin (Dpslo/lat = 3.350) than the Venetic (Dpven/lat = 5.295). This does not mean that Slovenian should be used for interpreting Latin, or that Latin should be used for interpreting Slovenian. In fact, the meaning of the words in both the two languages are known and more sophisticated linguistic methods can be used for comparing said languages. Figure 3 and Table 1 only indicate that Latin and Slovenian, in the limits of the Corpuses considered, have a closer alphabetic symbolic structure than the Latin and Venetic. However, Figure 3 and Table 1 also indicate that the Venetic, in the limits of the Corpuses considered, is closer to the Slovenian (Dpven/slo = 1.809) than to the Latin (Dpven/lat = 5.295). This: - proves that Venetic and Slovenian have a closer alphabetic symbolic structure; - disproves the above mentioned Lejeune’s affirmation [3]; and - supports the Bor’s affirmation [4], i.e. that a link between the Venetic and the ancient and consequently the modern Slovenian, its surviving dialects and archaisms actually exists. This confirms that Bor [4] was right in using similarities between Venetic and modern Slovenian, its surviving dialects and Slovenian archaisms, for interpreting the Venetic inscriptions. This also confirms the hypothesis set out by Šavli, Bor and Tomažič [4], that Venetic in Veneto (IT) rapidly disappeared due to the romanisation and the following barbarian invasions, while Slovenian partially preserved the Venetic.
AcknowledgementsWe wish to thank Prof. J. Rant for his general suggestion, at the end of the Conference in Ljubljana of the 10-11 October 2003, to use linguistic computational techniques for progressing in the understanding of the Venetic language and Prof. A. Perdih for his suggestions and advises concerning the present intervention. Bibliography1. G B Pellegrini, A L Prosdocimi, La Lingua Venetica, Vol. 1, 2, Istituto di Glottologia dell’Univ. di Padova, Circolo Linguistico Fiorentino, Padova-Firenze 1967 2. A Marinetti, Venetico 1976 – 1996. Acquisizioni e Prospettive – Protostoria e Storia del ‘Venetorum Angulus’, Atti del XX Convegno di Studi Etruschi ed Italici, 16-19 ottobre 1996, Pisa – Roma MCMXCIX, 391-436 3. M Lejeune, Les Inscriptions Vénetes, Univ. Degli Studi di Trieste, Del Bianco Editore, Udine 1965 4. J Šavli, M Bor, I Tomažič, Veneti. First Builders of European Community, Editiones Veneti, Wien 1996 (ISBN 0-9681236-0-0) 5. E Vetter, Die Herkunft des Venetischen Punktiersystems, Glotta 1920, XXIV, 114-133 6. V Vodopivec, Atestinske tablice verski in jezikovni pomniki naših prednikov, Proceedings of the First International Topical Conference, The Veneti within the Ethnogenesis of the Central-European Population, September 17/18, 2001, Založništvo JUTRO, Ljubljana, 2002, 167-181 (ISBN 961-6433-06-7) 7. A Ambrozic, G Tomezzoli, The “Tavola da Este” Inscription, Proceedings of the International Workshop, Traces of European Past, October 10/11, 2003, Založništvo JUTRO, Ljubljana 2004, 132-146 (ISBN 961-6433-34-2) 8. J Nerbonne, W Heeringa, Measuring Dialect Distance Phonetically, In: J. Coleman (ed.): Workshop on Computational Phonology, Madrid 1997, 12-15. Available as: http://odur.let.rug.nl/~nerbonne/paper.html 9. J Nerbonne, W Heeringa, Computational Comparison and Classification of Dialects, 2nd International Congress of Dialectologists and Geolinguists, Amsterdam 2002, 1-16 10. J Nerbonne, W Heeringa, E Van den Hout, P Van der Kooi, S Otten, W Van de Vis, Phonetic Distance between Dutch Dialects. In: Durieux G., Daelemans W. & Gillis (eds.), CLIN VI, Papers from the sixth meeting, University of Antwerp, Center for Dutch Language and Speech, Antwerp 1996, 185-202. Available as: http://odur.let.rug.nl/~nerbonne/paper.html 11. B Kessler, Computational Dialectology in Irish Gaelic, Proc. of the 6th Conference of European ACL, Dublin 1995, 60-66 12. W Heeringa, C Gooskens, Norwegian Dialects examined Perceptually and Acoustically, Computers and the Humanities, Groeningen 2003, 37, 295-297 13. J B Kruskal, An Overview of Sequence Comparison. In: Sankoff D, Kruskal J (eds.), Time Warps, String Edits and Macro Molecules. The Theory and Practice of Sequence Comparison, 2nd Edition, CSLI, Stanford 1999, 1-44 14. W Vieregge, A Rietveld, C Jansen, A Distinctive Feature Based System for the Evaluation of Segmental Transcription in Dutch, Proceedings of the 10th International Congress of Phonetic Sciences, Dordrecht 1984, 654-659 Supplementary materialsLatin Language Database (LLD), Slovenian Language Database (SLD), Venetic Language Database (VLD). The files containing these databases are available, free of charge, on request, at: marco@marcosilvestri.com or gtomezzoli@epo.org.
Povzetek Jezikoslovna računalniška analiza meri razdalje med nekdanjim venetskim, latinskim in slovenskim jezikom V tem delu ugotavljava jezikovne razdalje med nekdanjo venetščino, latinščino in slovenščino. Najprej sva ustvarila tri elektronske jezikovne zbirke: - Venetsko, ki vsebuje vse venetske napise iz del Pellegrinija in Prosdocimija ter Marinettijeve in raznih internetnih virov; - Latinsko, ki vsebuje dela naslednjih latinskih piscev: Plautus, Cato, Terence, Cicero, Caesar, Vergil, Propertius, ki so delovali med 300 – 0 pr. Kr., ko so latinščino in venetščino govorili še neodvisno; - Slovensko, ki vsebuje najstarejša slovenska besedila, kot so: Brižinski spomeniki, Rateški rokopis, Stiški rokopis ter Starogorski rokopis. Tehnike, ki so jo nedavno uporabili Nerbonne, Kessler, Heeringa in Vieregge, nisva mogla uporabiti, ker delitev na besede, izgovarjava, jezikovni razvoj in pravi pomen pik v venetščini še niso znani. Zato sva razvila enostavno metodo za oceno teh jezikovnih razdalj. S pomočjo evklidskega algoritma razdalj sva iz gradiva v teh zbirkah izračunala jezikovne razdalje med venetščino, latinščino in slovenščino. Izračun kaže, da je po teh razdaljah venetščina bliže slovenščini (1,809) kot latinščini (5,295). To spodbija Lejeunovo trditev, da "je venetščina italski jezik in ... bliže latinščini kot katerikoli drug jezik". Videti je, da je imel Bor prav, ko je izpostavil, da podobnosti venetščine s slovenščino, njenimi narečji in starinskostmi lahko uporabimo za razumevanje venetskih napisov. To bi tudi potrjevalo hipotezo Šavlija, Bora in Tomažiča, da je venetščina v sedanji italijanski pokrajini Veneto hitro izginila zaradi romanizacije, medtem ko je slovenščina obdržala dele venetščine.
|